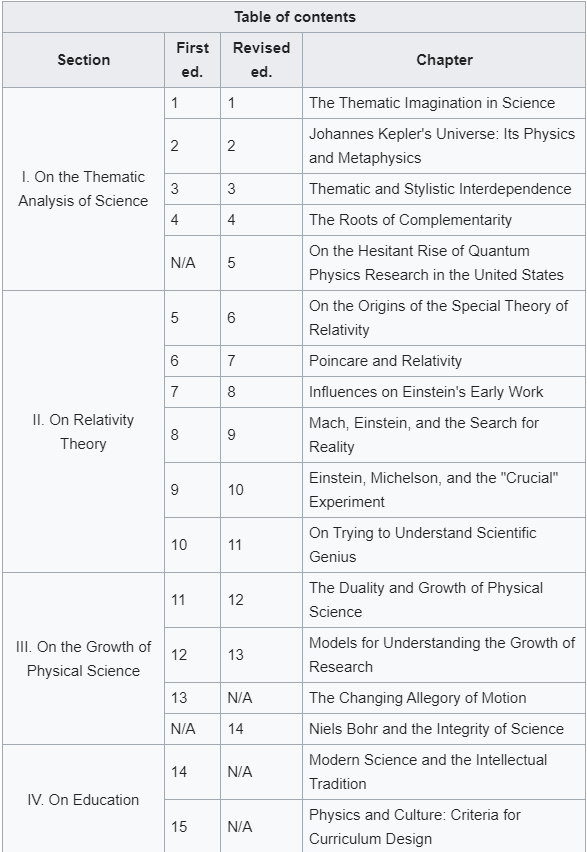
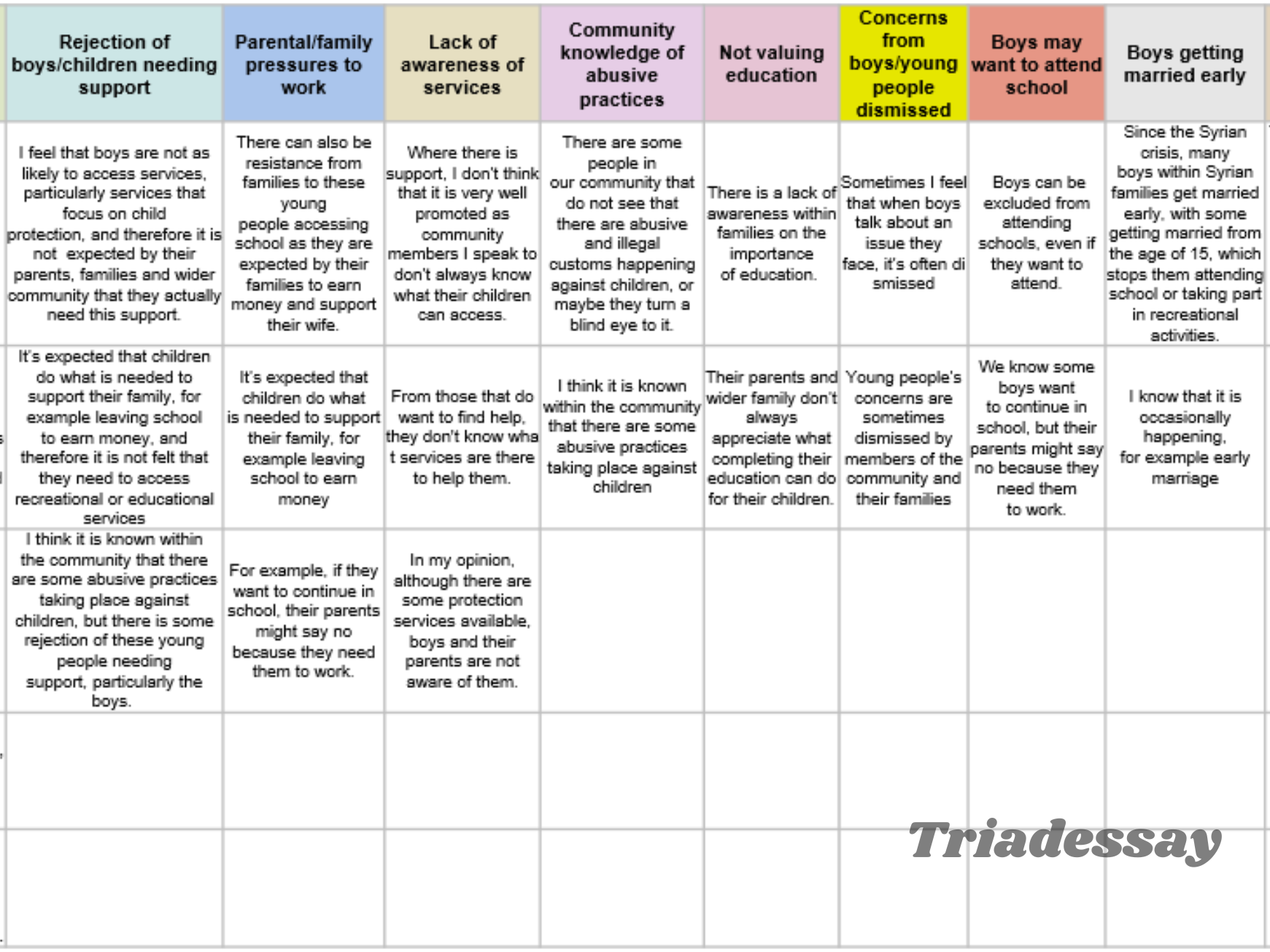
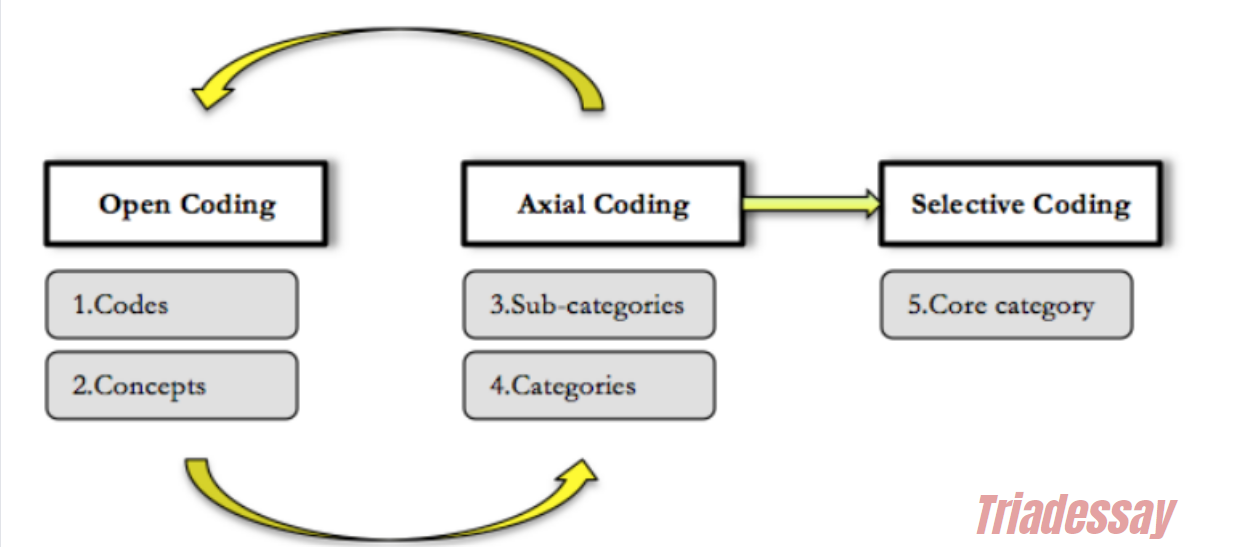
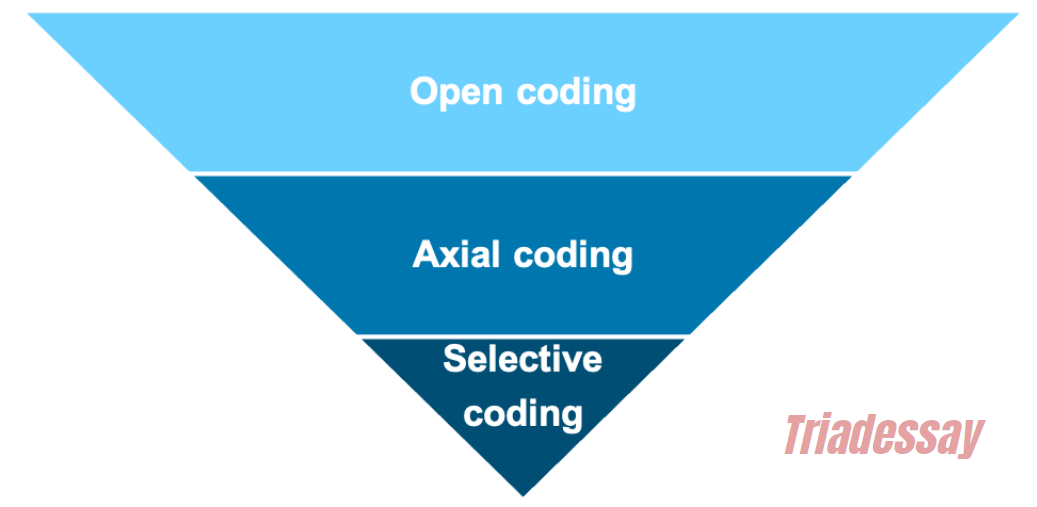
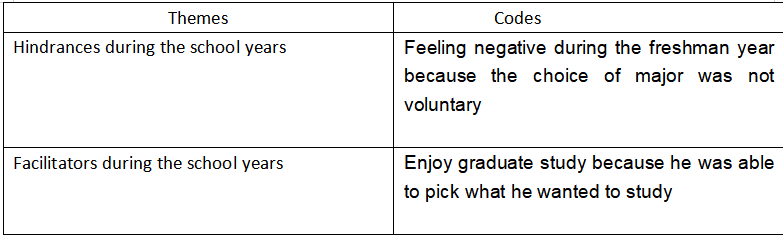
鉴于thematic analysis(主题分析法/TA)是在大学学习期间或是大家做科研时日常会学习和用到的一个研究方法,在这篇文章里小编将简短讨论关于thematic analysis的一些信息。包括thematic analysis的历史,主题分析法的入门,以及怎么正式应用主题分析法。 Table of Contents 什么是thematic analysis:主题分析法的历史和在research中的角色 此部分仅作科普用,大家觉得阅读起来无聊的话一定不要走开!请直接跳到下一部分:Thematic Analysis入门Thematic Analysis,也被称为主题分析法 或者 TA(thematic analysis的缩写),是research研究中用来分析“定性数据”的方法之一。简单来说,TA是通过分析数据/数据集中呈现的主题而得到结论或发现的一种分析方法。它是methodology中的一部分,是分析定性数据(qualitative data)的方法之一。我们在国外大学学习时,通常会接触到“单独的”、“并非基于一个正式研究的”、“迷你”主题分析法模拟训练。例如教授会给你一些定性数据(采访笔录,谈话内容,某一些人书面写出的文字等),然后让你基于明确的作业要求,用主题分析法去做分析并完成essay、lab report、assessment等。而在科研/research当中,主题分析法则是一个手段。研究者通常会用主题分析法(有时还会加上其他的数据分析方法)去分析为本次研究收集的数据,以此来得到结论/发现,然后将主题分析法的结果(results)展示在出版发布的学术文献当中。说到TA,那不得不提Gerald Holton(杰拉尔德·霍尔顿)的名字。Holton是一位德裔美国物理、历史学家。他早期的教育背景并不出众但可谓是后来居上,先是在牛津布鲁克斯大学拿到了certificate之后,进入了美国卫斯理大学并取得本科和硕士学历,之后在哈佛大学取得了博士学位。拿到PhD之后,Holton在哈佛担当教授,并将自己的一生致力于探索“科学的哲学和历史”。早在73年时,Holton就有了一个主题分析法的雏形。或者可以这样说:他出版的书《Thematic Origins of Scientific Thought: Kepler to Einstein》包含了TA(主题分析法)的雏形。在这本书中,Holton将一连串物理学历史中具有重要地位的文献,例如爱因斯坦的相对论论文,收集在了一起。而Holton不仅收集了这些文献,而是通过相似的主题(themata)将这些文献给归类在了一起。大家可以看看,下面的图片是这本书的目录: Again,霍尔顿将这些不同的文献通过最早的主题分析法归类在了一起并做了讨论。如相对论的文献被一同分到了第二章。说到这里,很多人也许对TA一知半解了,TA本质上来说就是研究数据呈现的主题而得到conclusion(s)或finding(s)的方法。同样,我们还需要注意霍尔顿在提出TA时一个重要的思想,那就是:科学不应仅仅是局限于可被完美定义,狭隘且单一的一个事物。相反,我们在进行科研时,应该注重或至少是be aware of 那些 creative unconsciousness 和 creative imagination,并尊重由于不同人的基因,perception(感知),背景,偏见等差异而造成的对现实的interpretation的差异 [1]。这个思想是具有开创性的。重要的是,它支配了定性研究的发展,为定性研究打下了基石。从很大程度上来说,定性研究也就是像霍尔顿说的那样:它是精彩的,有创意的,有趣的,heterogeneous而非homogeneous的。但话说回来,qualitative research(定性研究)通常也是带有更多的偏见的,是ideological的(带有稍强的意识形态的,如对平等,民主,公正等目标的追随,大家可以想想那些在监狱中采访性犯罪罪犯的女权研究者的目的,如Herman在1990年出版的书《Sex Offenders:A Feminist Perspective…》),而也是没办法去探寻定量研究能探寻的问题的。这里,我们马上进入下一个部分!!小编已经迫不及待了,大家将看到thematic analysis是怎么样一种精彩的且能够发掘研究者独特视角的分析方法!! Thematic Analysis入门 主题分析法小训练!在我们正式知道怎么样去thematically analyze data之前,我们先来做一个小练习吧!这是一个热身活动。请看以下的图片,用简单的词语描述每一个图片,将词语写在一个列表上。最后,将它们分类 利用以下格式来写出你的分类:类别1(填写名字)-子类别1:-2-3 类别2( )-子类别1:-2-3 类别3( )-子类别1:-2-3 大家可以用草稿纸来填写或在手机、电脑上直接填写,填写好后,可以点击下方,将展开的分类与自己的分类对比 A同学的分类 1:工作场所(9、10、16、14、15、2)子分类1:休息时的worker(10)子分类2:在工作的worker(9)2:学术场所(14、15、16、2)子分类1:实验室 [14、15]子分类2:教室 [16]3:户外场所(1、3、6、8、11、12)子分类1:独自一人 [6]子分类2:集体活动 [11、12] B同学的分类 1:女性(1、4、9、12、15、16)子分类1:亚裔子分类2:非裔2:男性(10)3:女性+男性(3)子分类1:小孩子分类2:大人 C同学的分类 1:带有大量绿色的图片(9、11、12)2:带有大量蓝色的图片(5、2、7)3:带有大量黄色的图片(4、6、8) 主题分析法的精彩:多元视角怎么样?展开上一部分后,ABC三位同学的分类有没有让你惊奇或是大跌眼镜?有没有感觉这分类方式是千奇百怪呀?这也就是Thematic Analysis的精彩之处。大家可以把以上的图片看作是我们的数据,而我们给数据分类的过程也就是我们在应用主题分析法的过程一方面,不同的人/研究者都受自己的感知,经历,思考,情绪等因素影响,从而有着独特的对数据主题的分类方式。另一方面,我们在做研究或小组作业时,几个不同的人/研究者对统一数据集(dataset)进行分析,之后再互相对照自己得出的主题分类,从而得出最丰富、客观、具有共同重复性的theme也是相当重要的。以上就是我们的thematic analysis入门。大家可以把上述的练习看作是一个迷你主题分析。实际上,主题分析的精髓也就是上述的活动。 Thematic Analysis怎么进行? 总的来说,thematic analysis大体可以分为这几个步骤:熟悉数据/familiarization生成编码/Generating Codes/Coding生成主题/Generating Themes回顾主题/Reviewing Themes对主题进行命名和定义/Defining and naming themes再次通过cross-examination,研究者合作等方式来确定最终的主题(此步骤适用于有多个研究者或group project的情况)将分析结果撰写(无论你最后是要写一篇essay,report,某风格的媒体/组织或个人文章,还是学术文献)值得注意的是,尽管这六个步骤是按顺序列出的,但主题分析不一定是一个线性的过程,换句话说,你在进行主题分析时,并不一定会一步一步地按照以上说到的步骤来做。厉害的主题分析法运用者在过程中会在各个阶段之间流畅地来回切换,并在出现新见解时进行调整以产出最丰富的,最有洞察力的结果。例如 我现在分析一长篇interview的谈话内容,正在生成主题,但是我觉得好像受到了阻碍,并不能很顺利地生成清楚的or有意义的主题,我会重新回到第一步,再次熟悉数据。这一点可能现在说起来比较抽象,在大家看完整篇文章后,和在自己正式开始做主题分析时会更好理解。还有一点,不要看主题分析法只有这短短的7个步骤,每一个步骤都是蕴含着特定的技巧和一些子步骤的,小编待会儿会用Coding(生成编码)这个步骤来举例。下面,让我们正式来看看每个步骤怎么做吧!注******************:以下步骤很难脱离详细的定性数据来讲,所以小编加入了一些虚构的定性数据,以便更好说明。 第一步:熟悉数据/Familiarizing Data 顾名思义,这一步就是我们拿到数据后开始做的第一步。Again,这个数据肯定会是定性数据,而它具体是interview transcription,personal reflection,(field)observation note,或甚至是online forum comment,就取决于教授给你的数据和你的研究收集的数据了。 熟悉数据时,每个人都有不同的方法。但不可否认的是,最实际的方法就是通读数据。通读所有的文字,像看一本书一样!当然,还有的富含经验的研究者会使用精读等方式来熟悉数据。这一步给下面几步打基础。你对数据的熟悉程度会直接影响你之后生成编码,生成主题的顺利程度,所以,把数据当作你的朋友,跟它建立起一个亲密的关系是至关重要的! 第二步:编码(Coding)OR(Generating Codes) 编码是什么意思?简单来说,它就是对数据做标注,为你觉得有意义的句子,段落设计标签或“代码”。也可以理解为annotate data。而且编码通常没有严格的单一规定,没有绝对的方法可言。这可以简单到跟做读书笔记一样,也可以复杂到例如语言学家用专业知识来对句型,动词用法,词态等元素进行详细标注,又或是心理学家对咨询谈话用心理学专业术语+自己的想法进行标注。最重要的是,编码是按照你的研究问题来进行的。举例,你想探索某个人群对于学习方法的解释,那么你在编码的过程中会时时刻刻将学习方法这个词放在自己脑中,有意识地去识别跟学习方法有关的文字。大家看看以下例子,这是非常简单的一个coding,假设下列interview的数据是你需要分析的数据,那么电子版的编码看起来类似于这样: 当然,简单的coding也可以做的非常美观,说到底,thematic analysis是精致的!例如一些人会用不同颜色去highlight数据: 在进行下一步前请注意!如果你的数据很多,例如上几十页,上几百页的文字,那么你在通篇编码完成以后,最好能将所有的笔记放到一个excel里,不然的话,下一步将会进行地异常困难,别问我为什么,小编是过来人:)。一个基于自己的codes的Excel表格如下图所示: 问题来了,那动辄上几十页,上百页的数据我全要code吗?有些同学可能会问了(尤其是手上数据极多的人),那Code所有的数据不是要累死人且没有意义吗?几个interview那么多话,我句句话都要code一遍吗?事实上,你并不需要code所有的内容,相反,我们应该去有选择性地编码。所以,联系到之前,编码的过程是需要依据你的研究问题来进行的,有选择性的。而且这也就是为什么小编强调了虽然TA看起来只有简简单单几个步骤,但每个步骤要求的能力和细节都是值得探讨的。在这里,这篇文章就详细讨论一下coding。 主题分析过程中的数据编码涉及系统地识别和标记数据的相关部分。此过程不仅涉及用代码标记数据,还涉及深入研究内容以辨别潜在的模式和含义。编码为后续组织代码和主题的生成奠定了基础。它需要一种细致和迭代的方法,对数据进行多次审查,以确保代码得到准确和全面的应用。Coding有三个关键阶段:对数据进行编码、识别数据之间的模式、解释数据之间的模式。1. 编码数据对数据进行编码是指阅读数据集(例如采访记录、现场笔记、文档、社交媒体帖子等)以识别有趣的摘录并分配捕获与研究相关的每个数据段的本质的代码的过程问题或目标。在此阶段,目标是尽可能广泛和包容地对定性数据进行编码,而不用担心不同代码之间的特殊性或潜在重叠。编码人员应该以开放的心态对待数据,让数据本身指导新代码的创建。代码还可以从数据中存在的更多潜在含义中产生,以便研究人员可以利用他们的概念或理论理解来创建代码。此阶段本质上是探索性的,目标是创建能够捕获数据的丰富性和多样性的代码。在这个时候,确实选择性不大,这也可以看作是熟悉数据的第二个迭代步骤,因为我们还是在尽可能的take in更多的信息,并不加选择地(indiscriminately)进行标注编码。2. 识别数据中的模式对数据进行扩展编码后,研究人员可以使用这些代码来识别主题或模式。这通常还涉及完善代码并开始缩小最适合研究问题或目标的代码范围。此阶段要求编码人员决定保留、组合或丢弃哪些代码。研究人员可以在修改代码时开始识别模式:虽然代码可能捕获一个想法,但主题围绕一个中心组织概念汇集了多个想法。在这个阶段,研究人员开始创建临时主题,随着研究人员解释分析的进展,这些主题将继续完善。这个时候我们的“选择性编码”(selective coding)概念就被体现出来了!3. 对编码的数据进行解读在深入分析数据,编码和对模式进行识别后,我们可以通过解释或理解新出现的模式来充分发展完善我们的分析。重新审视每个主题中捕获的数据摘录非常重要,这能确保主题有效地描绘支持数据中的中心组织概念。这也是我们在命名和定义我们的主题的时候,为什么涉及修改、组合甚至丢弃一些主题;我们的目标是建立一组主题,讲述有关数据的连贯且有意义的故事。不同人的主观经验在解读模式(pattern)中也发挥着重要作用,我们可以批判性地反思他们如何以及为何做出解释。而对模式和主题充分的解读也在很大程度上依赖于撰写分析,因为将一个人的想法转化为文字通常可以澄清新的见解,暴露不一致的地方,并可以有效地将关键发现和支持数据联系起来。在你完成了编码,也把所有的code放到了excel表格里去之后,我们就可以进行下一步了。主要的Coding概念:Open Coding、Axial Coding、Selective Coding Open Coding (开放式编码)开放编码: 开放编码是数据分析的初始阶段,研究人员将数据分解为离散的部分,仔细检查,并将标签(或代码和annotation)分配给代表特定想法、主题或概念的数据片段。 open coding的目的:在没有任何先入为主的假设(predetermined beliefs)的情况下识别和分类数据中的所有潜在主题或概念。这是一个探索阶段,而这个阶段中,你将自己的心放开,去发现并接受数据中新的见解。open coding的过程:在开放式编码过程中,我们一般会逐行、逐段地浏览数据,标记看起来重要或有趣的部分。这些代码通常是描述性的,涵盖了数据中存在的各种想法、感受、价值观、信仰、现象等。Axial Coding(轴向编码)轴向编码是我们开始组织和关联开放编码过程中识别的代码的下一阶段。它涉及重新组装数据以探索不同代码、概念和类别之间的关系。 轴向编码的目的:将不同的代码连接到更广泛的类别中,并了解它们之间的关系。此阶段有助于在更抽象的主题或子主题下完善和分组代码。 过程:在轴向编码期间,我们可能会寻找模式、原因和结果,或将代码链接在一起的任何上下文条件。我们开始提出诸如“这些代码如何相关?”之类的问题。或“什么条件导致这个主题出现?” 鉴于高阶TA通常涉及NVivo的使用,axial coding的过程大家可以在Nvivo中使用relationship功能完成。Selective Coding(选择性编码):定义:选择性编码是研究人员确定封装数据主要故事的中心或核心主题的最后阶段。此阶段涉及整合和完善轴向编码期间确定的主题。 目的:目标是选择对研究问题至关重要的最重要的主题,并将它们编织成一个连贯的叙述或理论框架来解释整个数据和回答我们的research question(RQ)。 流程:在选择性编码中,我们专注于开发和完善核心主题,并确保它们与整体分析保持一致。此阶段可能涉及丢弃不太相关的代码并进一步澄清将构成你的发现基础的关键主题。有趣的是,这三个过程可以被想象为是一个funnel,它们是由general到specific的一个过程。我们的code慢慢变少,或被归类到一起,直至我们得到最终的结论。 第三步:生成主题(Generating Themes) 在你完成了编码后,是时候将它们分成主题了。这个时候,或许我们的总进度条已经到达30%这个位置了。分成主题,怎么分?我们始终要记住,我们最后产出的作品(essay,article,lab report)等就是要展示(present)我们在数据中找到的一系列的重复的,主要的主题(recurring overarching theme)。所以,我们需要围绕着这个目的,将我们手上收集好的code进行分类,哪些code是可以被分为一个主题的?将它们归类为几个主题,并对主题进行一个初步的命名。注意,主题不在多,在于它是否能精确地概括从属于它的所有codes。 在这里,还需要注意,主题也分为主要主题(main theme)和次主题(sub-theme)。大家读到这儿,是否有想到前一个章节中的迷你主题分析法训练,where小编让大家将一组图片分类呢? 在此过程中,同学们可能会发现某些代码过于模糊或不够相关,因此可以将其舍弃。其他一些代码则可能发展成独立的主题。最终,你需要根据研究目的,创建出能够为数据提供有用信息的主要主题和次主题。 第四步:回顾主题(Reviewing Themes)确保主题准确反映数据是关键。返回数据集,验证这些主题是否真实存在于数据中,需确保没有遗漏任何信息。考虑对主题进行调整,例如分拆、合并或重新定义,以提升其有效性和准确性。在审查的过程中,如果发现主题存在问题,可以采取以下措施:分拆:将主题细分为更具体的部分。合并:将相似主题合并,提高一致性。丢弃:去除不再适用的主题。创建新主题:根据数据的需求,构建新的主题。在这里,小编用之前的一个triadessay的以往案例来解释。大家可以看到,作者已经提取出了主题和编码,并将这两个编码分成了两个不同的主题。 但是,在经过回顾主题后,作者觉得这两个主题可以合并成一个大类,那就是总的学习经历。 这也就是回顾主题过程中合并主题的一个例子。而事实上,回顾主题过程中,你就是会不断地抛弃主题,合并主题,产生新主题,拆分主题。 第五步:定义和命名主题虽然在上一步中,我们大概率已经有了不同主题的名字,但是为了研究结果的丰富性和准确性,我们最好能使出浑身解数再为每个主题进行命名和定义。而且话说回来了,你在回顾了主题后,可能又产生了一些新的主题,或是抛弃了一些主题。这个时候出现的这些新主题就需要你再进行精确有概括性的命名和定义。定义主题时,我们需要明确每个主题的具体含义,make一个mental note,你的这些主题到底意味着什么?对你来说它们的本质是什么?对研究问题假设来说,它们本质是什么?命名主题需要为每个主题提供一个简洁易懂的名称。小编的建议是不超过10个单词,虽然这个标准都有一点宽松了。尽量简洁!有什么细枝末节的事是我们不能用一个词概括的???精神分裂症患者讨论他的童年遭遇,服药经历,副作用,住精神病院经历,物质滥用史,这些就一个词:Experience!教育工作者讨论怎么样毕业,拿到资格证,到大学教书,当TA,遇到学生plagiarism,etc. 这些也就一个词:Experience!哈哈,请忽略这两段。虽然我们需要在命名时精简,我们也需要注意细节性,那就是,怎么样用简短的话语最大程度上展示最多的细节。 第六步:撰写你的成果到这一步时,可以说你的任务已经完成70%了。在撰写我们的成果时,我们通常会把数据展示在结果(results)部分。但不可置疑的是,我们需要有一个总体全面的思维。换句话说,你的数据展示是离不开其它部分的,例如methodology,abstract,introduction,data analysis。小编假设你是写的一篇lab report或是学术essay。我们在写的时候首先需要引入研究问题、目标和方法。这为读者提供了背景和理解框架。接下来,要包括方法论部分,具体说明数据收集的方式,比如使用observation,interview,survey等。有的时候,我们同样需要详细描述整个主题分析的过程。例如我们先熟悉数据,然后code,怎么code的(是用codebook,map还是像Nvivo一样的分析软件),怎么得出主题的。结果部分逐一探讨每个主题,涵盖主题出现的频率和含义,同时提供数据示例(也就是原版数据里的片段,你code的那些话)作为支持证据。最后,通过总结主要发现,展示分析如何有效回答研究问题。这就完了!希望这篇文章能够至少让你对主题分析法有一个大概的了解。同时,我们提供大量的主题分析法练习以及配套的定性数据,以供你练习使用,详情可以咨询客服了解。我们同样有大量的定性分析essay案例,如conversation analysis(对话分析),discourse analysis(话语分析/论述分析),thematic analysis essay案例,和qualitative lab report供大家查看。大家如需主题分析法辅导,thematic analysis代写、NVivo代做、NVivo辅导、Nvivo代分析、thematic analysis辅导,Content Analysis代写/辅导,欢迎联系我们。 上一页 文章 经济学代写 下一页 文章 Tableau代做,tableau代写,tableau帮做